
Snowflake
This guide explains how to export data from Snowflake to Auxia's GCS bucket for ingestion.
1. Overview
In this approach, data is exported from Snowflake directly to Auxia's GCS bucket using Snowflake's native COPY INTO command. Auxia then ingests the data from there.
Flow:
Client (Snowflake) Auxia
│ │
│ │ 1. Provide GCS bucket path
│<─────────────────────────────────────│
│ │
│ 2. Create storage integration │
│ (Snowflake generates a GCP │
│ service account) │
│ │
│ 3. Retrieve & send service account │
│─────────────────────────────────────>│
│ │
│ │ 4. Grant bucket access to
│ │ service account (via IAM)
│<─────────────────────────────────────│
│ │
│ 5. Set up scheduled exports │
│ │
│ Data flows to GCS │
│═════════════════════════════════════>│
2. What Auxia Provides
Auxia will provide:
- Destination GCS bucket path (e.g.,
gcs://<your_bucket_path>/)
Contact your Auxia solutions engineer to obtain this.
3. Prerequisites
- The user performing this setup must be granted the
ACCOUNTADMINrole (required for creating storage integrations). - A running Snowflake warehouse for compute.
4. Running SQL in Snowflake
All SQL commands in this guide are executed using Snowflake's web interface (Snowsight).
To open a SQL worksheet:
-
In the left navigation menu, select Projects → Worksheets
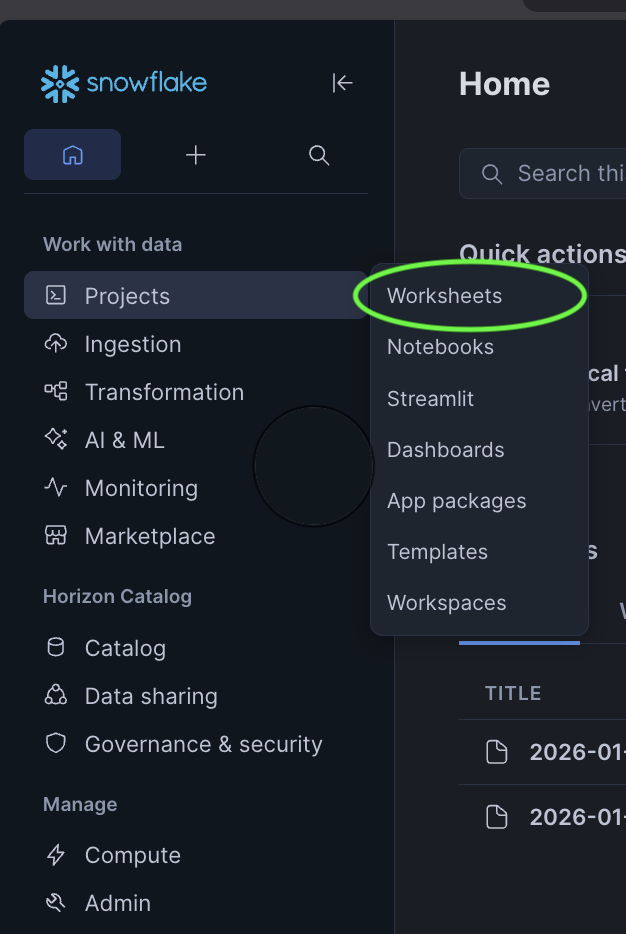
-
Click the + button in the top-right corner
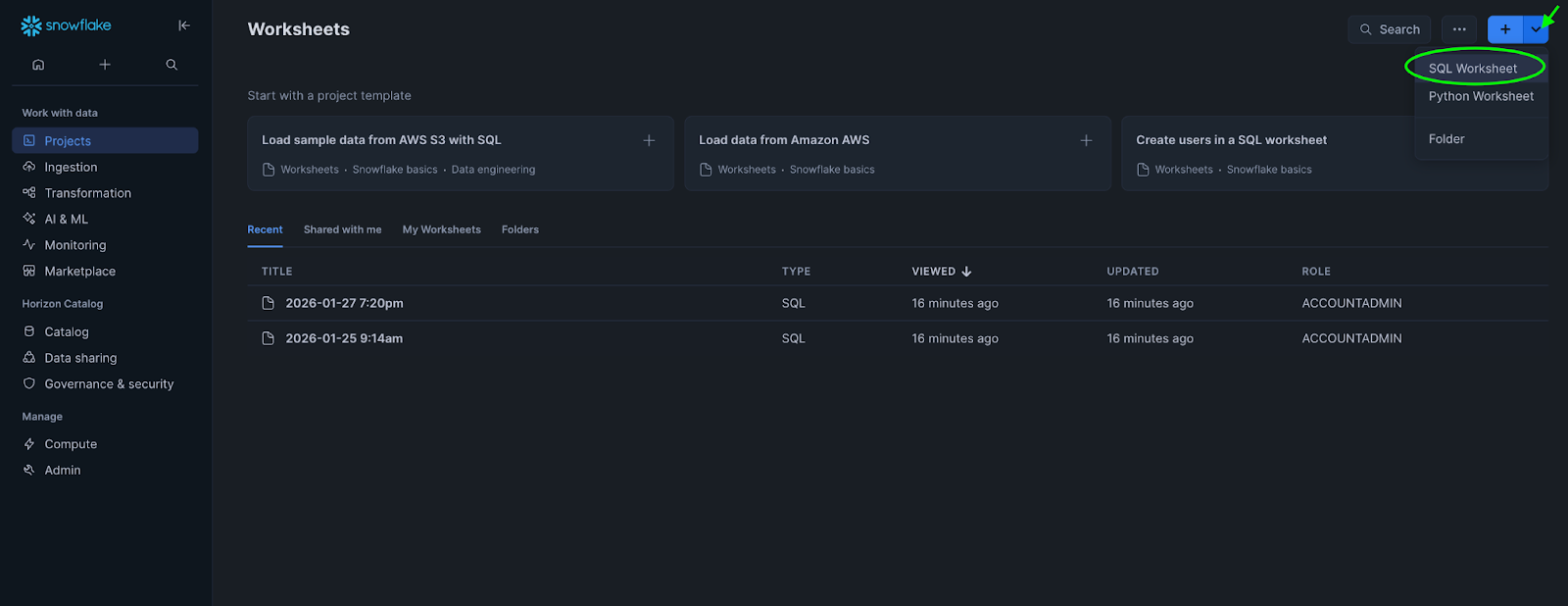
-
Select SQL Worksheet
Before running SQL commands:
-
In the top-right corner of the worksheet, select your Role (use
ACCOUNTADMINfor storage integration commands)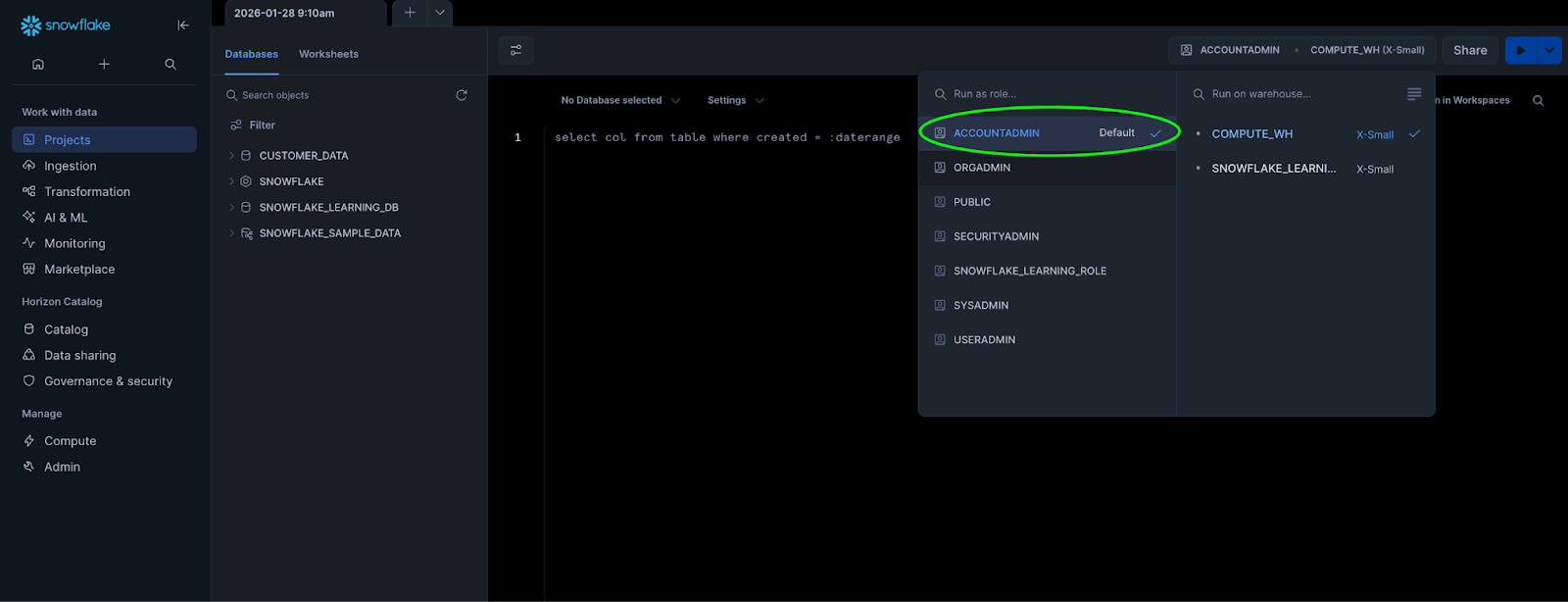
-
Select a Warehouse for compute resources
-
Optionally select a Database and Schema context
To execute SQL:
-
Place the cursor on the statement and click the Run button (or press
Cmd+Enteron Mac /Ctrl+Enteron Windows)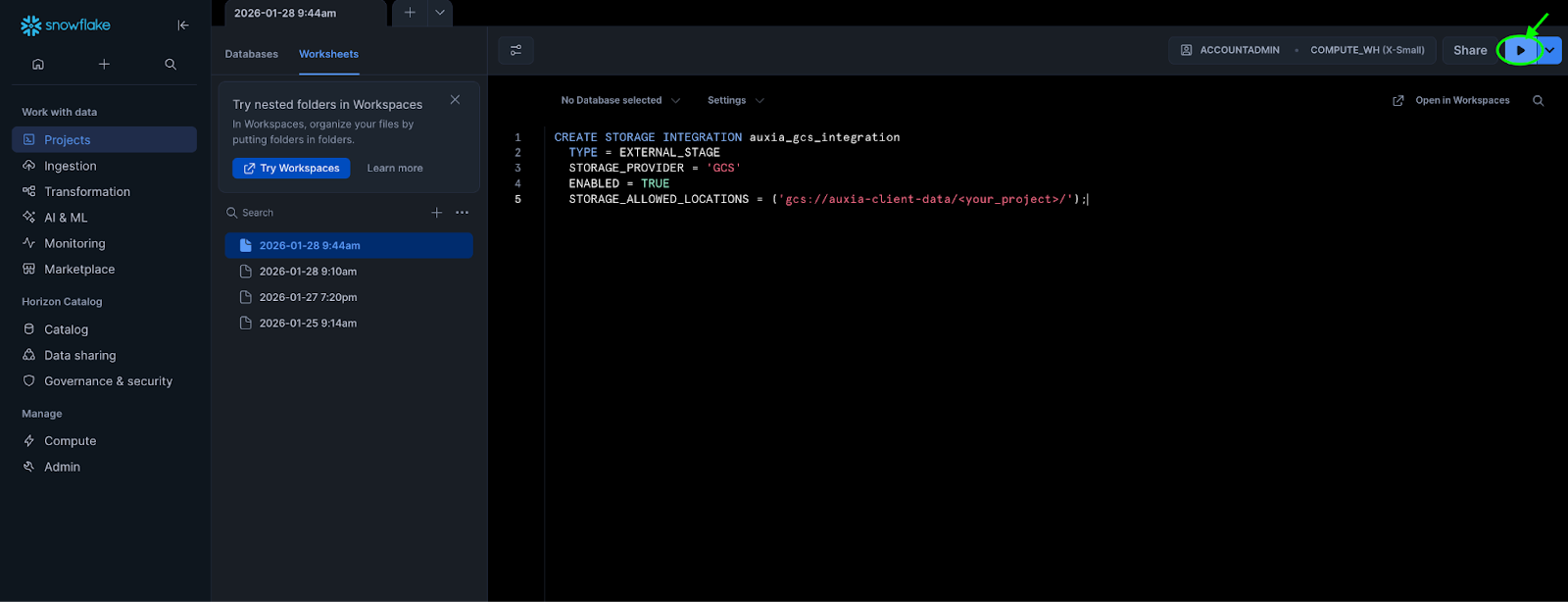
-
To run all statements, select all text first
5. Required Actions
Step 1: Create a Storage Integration
GCS bucket paths copied from the Google Cloud Console use the gs:// prefix. Snowflake requires the gcs:// prefix instead.
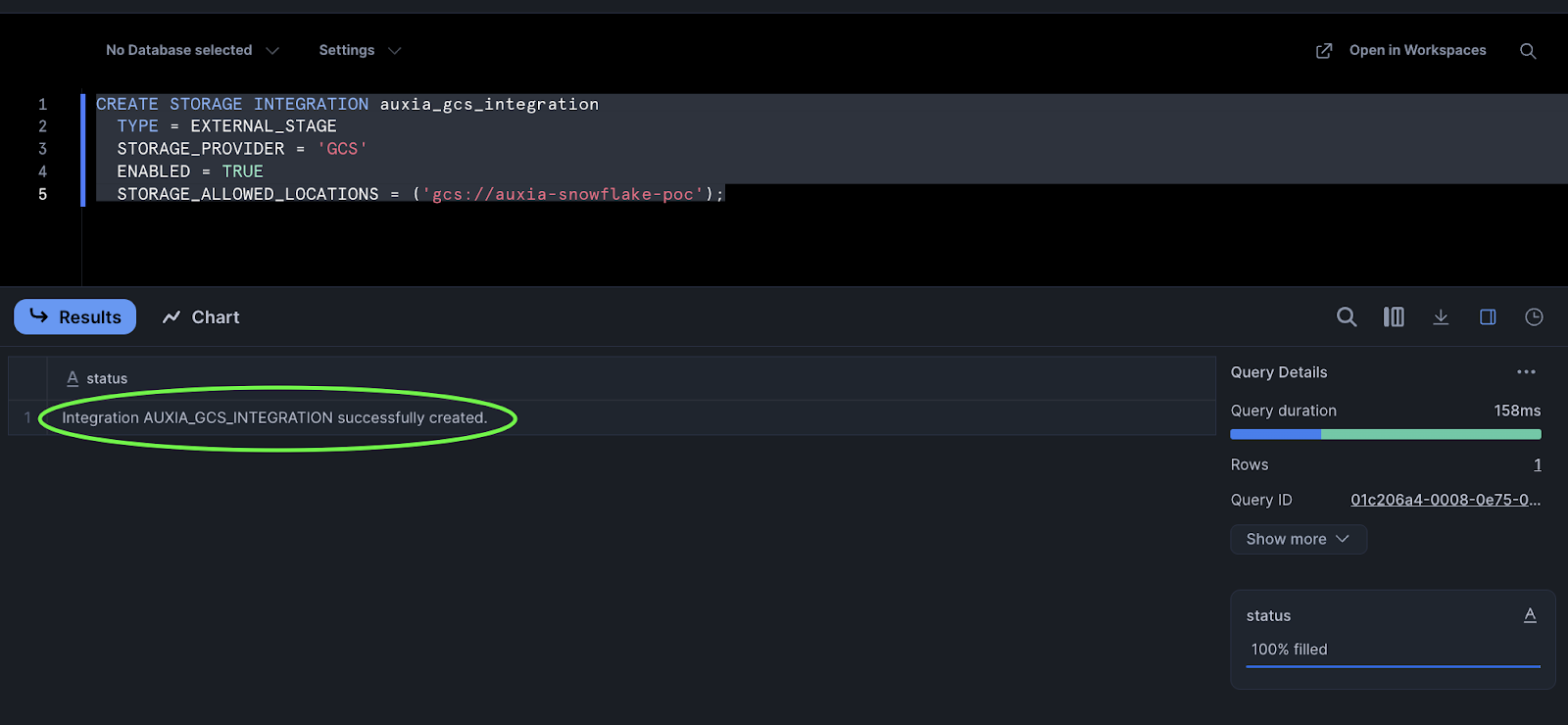
Run the following SQL in a worksheet with the ACCOUNTADMIN role selected:
CREATE STORAGE INTEGRATION auxia_gcs_integration
TYPE = EXTERNAL_STAGE
STORAGE_PROVIDER = 'GCS'
ENABLED = TRUE
STORAGE_ALLOWED_LOCATIONS = ('gcs://<your_bucket_path>/');
A successful execution returns the following:
Step 2: Retrieve and Send the Service Account to Auxia
Run the following SQL to retrieve the Snowflake-generated GCP service account:
DESC STORAGE INTEGRATION auxia_gcs_integration;
Locate the STORAGE_GCP_SERVICE_ACCOUNT row and copy its property_value:
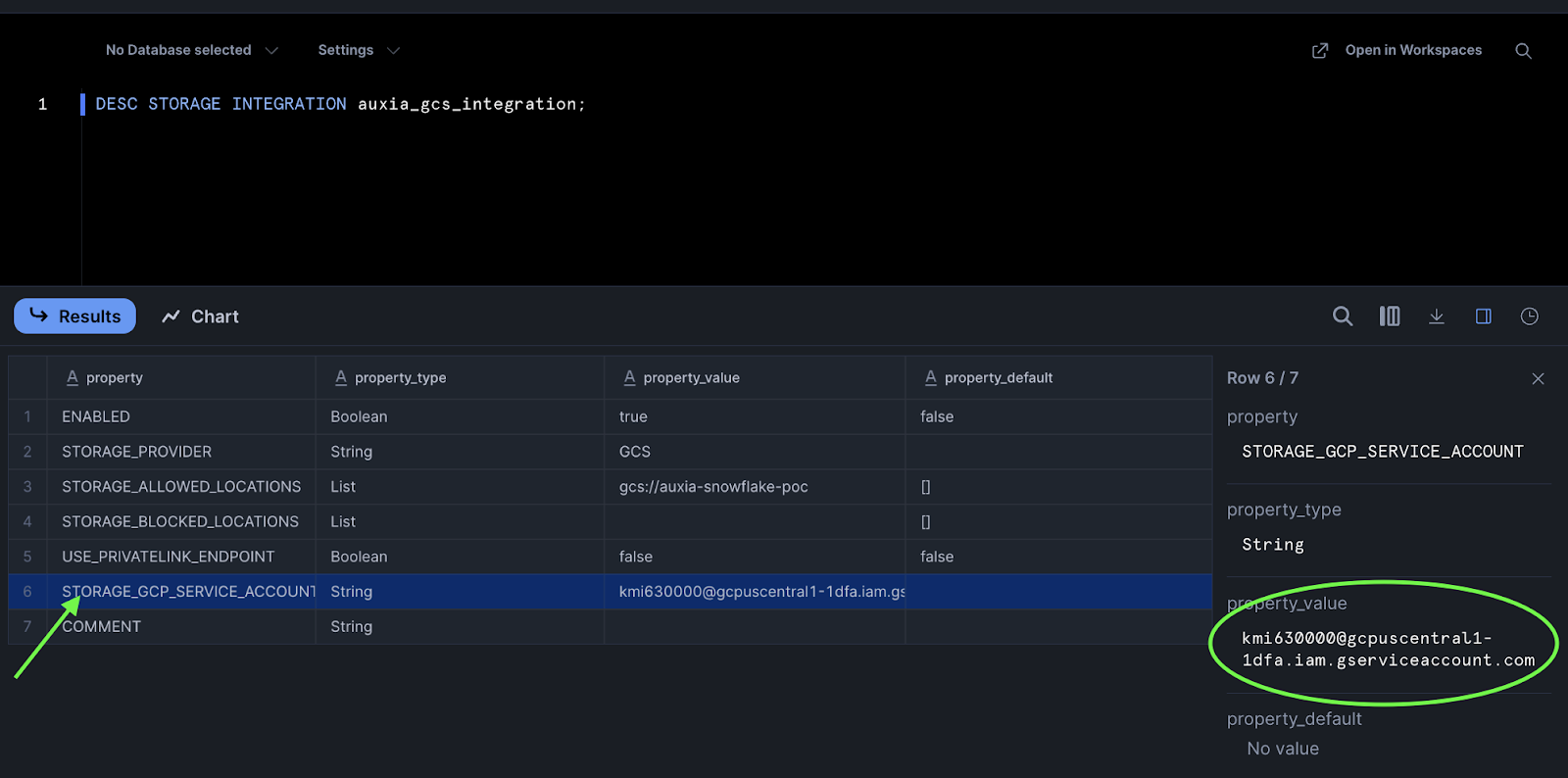
Send the copied value to Auxia.
Auxia will grant this service account write access to the destination bucket via GCP IAM.
Step 3: Set Up Scheduled Export
Once Auxia confirms write access is granted, set up a scheduled export to deliver data to the GCS bucket in the format specified below.
Cost considerations:
- Warehouse compute: Each task execution consumes Snowflake credits based on warehouse size and runtime. Billing is per-second with a 1-minute minimum per execution.
- Data egress: Snowflake charges per-byte egress fees for cross-region or cross-cloud data transfers. Same-region transfers are free.
- Recommendation: Use an appropriately sized warehouse (e.g., X-Small for small datasets) and consider export frequency based on data volume.
Data format requirements:
File Format
- Parquet (required) — must be specified explicitly via
FILE_FORMAT = (TYPE = PARQUET)in the export query. Snowflake uses Snappy compression by default for Parquet files.
Partitioning
Data must be partitioned by UTC date (dt=YYYY-MM-DD/) or UTC date and hour (dt=YYYY-MM-DD/hr=HH/). Each folder should contain data that was added to Snowflake during that UTC hour (for hourly exports) or UTC day (for daily exports).
Daily partitioning:
<your_bucket_path>/
data/<table_name>/
dt=2026-01-24/
data_0_0_0.parquet
dt=2026-01-25/
data_0_0_0.parquet
dt=2026-01-26/
data_0_0_0.parquet
Hourly partitioning:
<your_bucket_path>/
data/<table_name>/
dt=2026-01-26/
hr=00/
data_0_0_0.parquet
hr=01/
data_0_0_0.parquet
hr=14/
data_0_0_0.parquet
Data Requirements
- Treat exported files as immutable — do not modify or delete after writing
- Use UTC timestamps for all partitioning
How to achieve this:
The export should filter for new data added since the last export. A common approach is to use a timestamp column (e.g., export_timestamp) that records when each row was inserted into Snowflake, and filter based on that column to extract data for the corresponding UTC time period. The exact filtering logic will depend on your data structure and pipeline.
Below are Snowflake Task examples to help you get started. The schedule, filtering logic, and export paths shown here are illustrative — modify them to fit your data pipeline.
Sample: Hourly Export
-- Set database context
USE DATABASE <your_database>;
USE SCHEMA <your_schema>;
CREATE OR REPLACE TASK hourly_export_task
WAREHOUSE = <your_warehouse>
SCHEDULE = 'USING CRON 5 * * * * UTC' -- Example: runs once per hour, at HH:05 UTC
AS
DECLARE
export_ts TIMESTAMP_NTZ := DATEADD(hour, -1, CONVERT_TIMEZONE('UTC', CURRENT_TIMESTAMP()));
export_date VARCHAR := TO_CHAR(export_ts, 'YYYY-MM-DD');
export_hour VARCHAR := TO_CHAR(export_ts, 'HH24');
BEGIN
EXECUTE IMMEDIATE '
COPY INTO ''gcs://<your_bucket_path>/data/<table_name>/dt=' || export_date || '/hr=' || export_hour || '/''
FROM (
SELECT *
FROM <your_database>.<your_schema>.<table_name>
-- Convert export_timestamp to UTC (replace <source_timezone> with your timezone, e.g., America/Los_Angeles)
WHERE DATE(CONVERT_TIMEZONE(''<source_timezone>'', ''UTC'', export_timestamp)) = ''' || export_date || '''::DATE
AND HOUR(CONVERT_TIMEZONE(''<source_timezone>'', ''UTC'', export_timestamp)) = ' || export_hour || '
)
STORAGE_INTEGRATION = auxia_gcs_integration
FILE_FORMAT = (TYPE = PARQUET)
HEADER = TRUE
';
END;
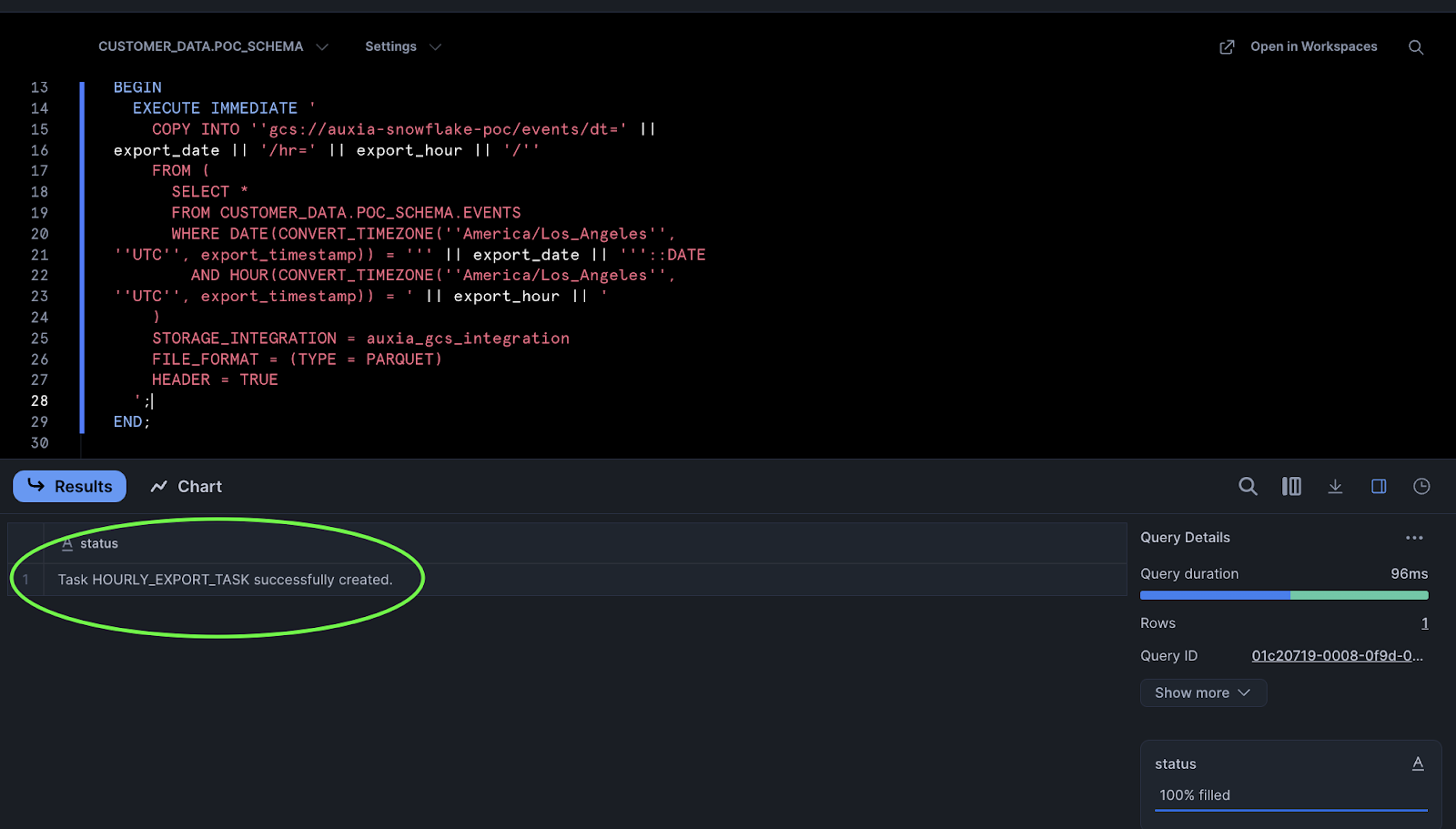
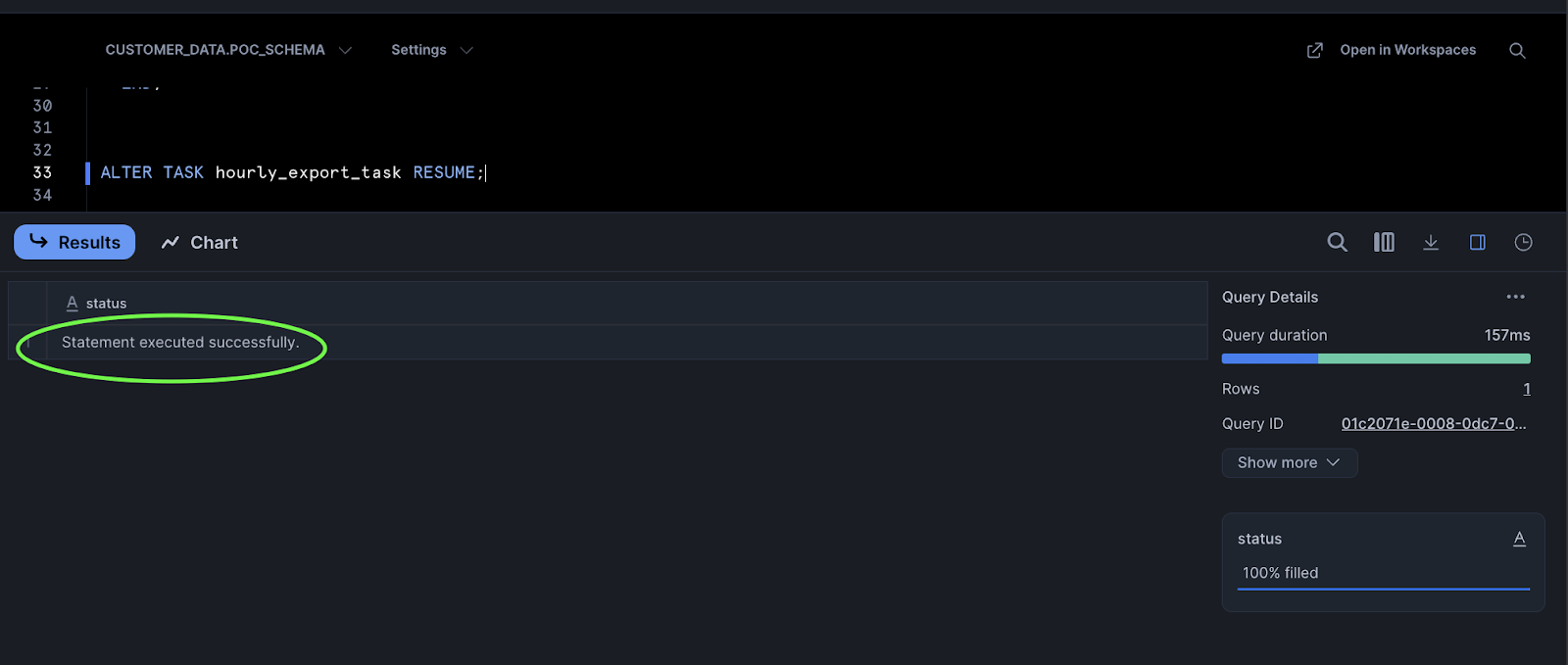
Once the task is created, resume it to start execution:
ALTER TASK hourly_export_task RESUME;
Sample: Daily Export
-- Set database context
USE DATABASE <your_database>;
USE SCHEMA <your_schema>;
CREATE OR REPLACE TASK daily_export_task
WAREHOUSE = <your_warehouse>
SCHEDULE = 'USING CRON 30 0 * * * UTC' -- Example: runs once per day, at 00:30 UTC
AS
DECLARE
export_date VARCHAR := TO_CHAR(DATEADD(day, -1, CURRENT_DATE()), 'YYYY-MM-DD');
BEGIN
EXECUTE IMMEDIATE '
COPY INTO ''gcs://<your_bucket_path>/data/<table_name>/dt=' || export_date || '/''
FROM (
SELECT *
FROM <your_database>.<your_schema>.<table_name>
-- Convert export_timestamp to UTC (replace <source_timezone> with your timezone, e.g., America/Los_Angeles)
WHERE DATE(CONVERT_TIMEZONE(''<source_timezone>'', ''UTC'', export_timestamp)) = ''' || export_date || '''::DATE
)
STORAGE_INTEGRATION = auxia_gcs_integration
FILE_FORMAT = (TYPE = PARQUET)
HEADER = TRUE
';
END;
Once the task is created, resume it to start execution:
ALTER TASK daily_export_task RESUME;
A successful task creation returns the following:
6. Monitoring Task Execution
To verify the export task is running correctly, use the following SQL commands.
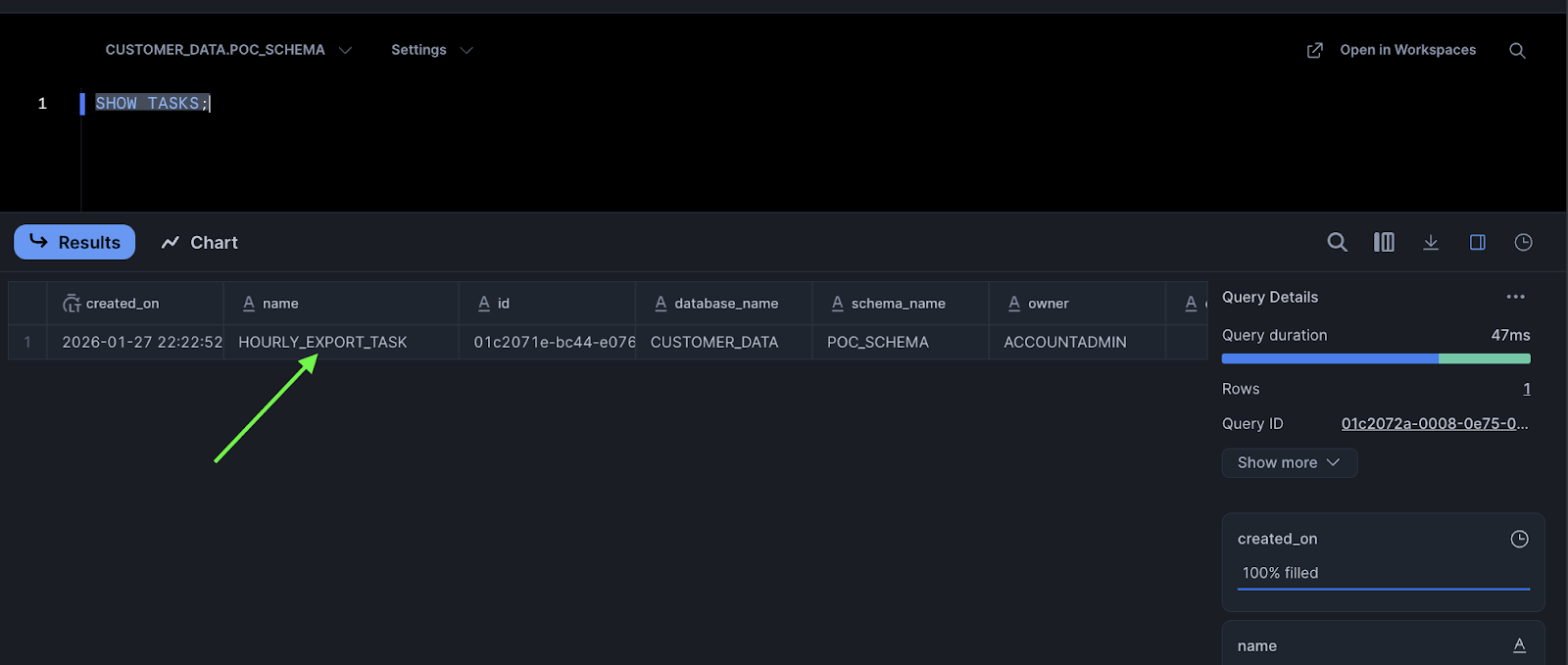
List all tasks:
SHOW TASKS;
The task created earlier should appear in the results:
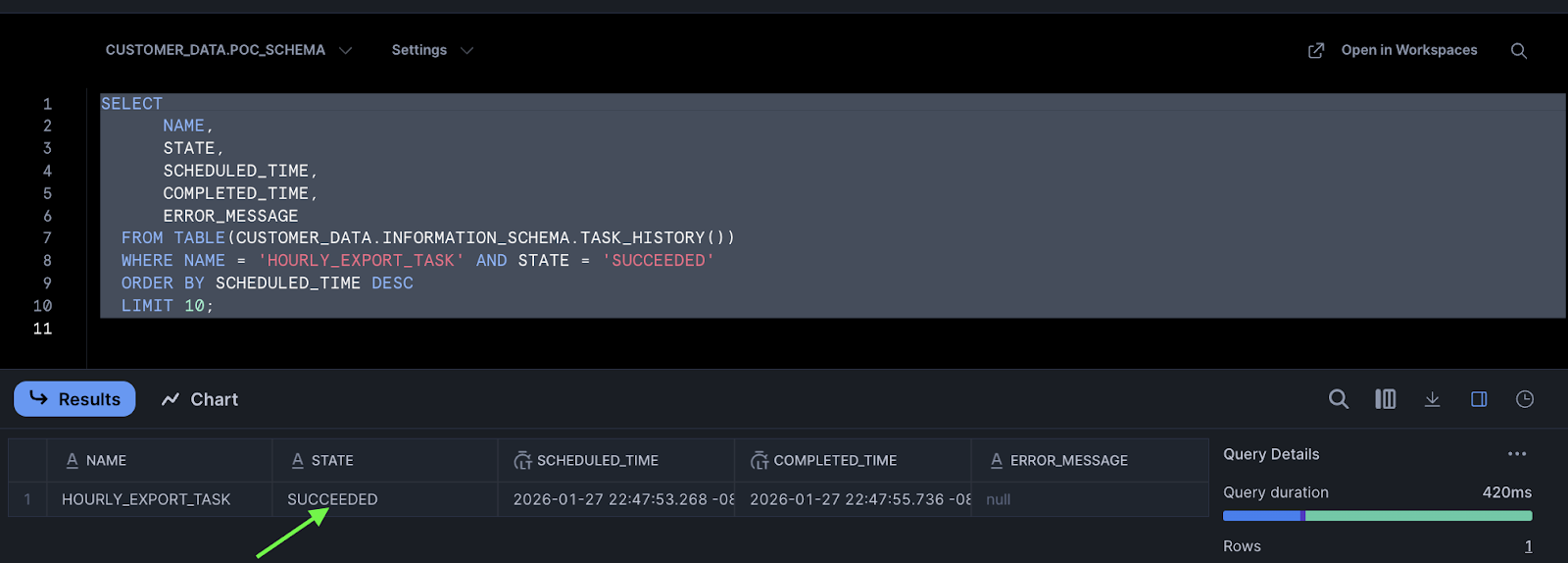
View recent task execution history:
SELECT
NAME,
STATE,
SCHEDULED_TIME,
COMPLETED_TIME,
ERROR_MESSAGE
FROM TABLE(<your_database>.INFORMATION_SCHEMA.TASK_HISTORY())
WHERE NAME = 'HOURLY_EXPORT_TASK'
ORDER BY SCHEDULED_TIME DESC
LIMIT 10;
Successful task executions appear with SUCCEEDED in the STATE column:
Suspend or resume a task:
-- Suspend
ALTER TASK hourly_export_task SUSPEND;
-- Resume
ALTER TASK hourly_export_task RESUME;
7. Confirm with Auxia
Once the export task is running and verified, notify Auxia and confirm:
- Export frequency (hourly or daily)
- Table(s) being exported
8. Recommended Practices
- Use Parquet format — Snowflake compresses Parquet files with Snappy by default
- Partition by UTC date (daily) or UTC date/hour (hourly)
- Ensure immutability — once a file is written, it should not be modified or deleted
- Use UTC timestamps — all partitioning should be based on UTC time
- Monitor task execution — regularly check task history for failures or delays
9. Summary
| Step | Action | Owner |
|---|---|---|
| 1 | Provide GCS bucket path | Auxia |
| 2 | Create storage integration | Client |
| 3 | Retrieve and send service account to Auxia | Client |
| 4 | Grant bucket access to service account (via IAM) | Auxia |
| 5 | Set up scheduled export task | Client |
| 6 | Confirm export is running | Client |
Need Help?
Contact support@auxia.io or your Auxia solutions engineer.